# 1~10000 합
odd_sum <- sum(seq(1:10000))
odd_sum
sum(seq(1,10000,2))
# 1~10000 합 (for문 사용)
sum <- 0
for(i in 1:10000) {
sum <- sum + i # sum에 i 값을 누적
}
print(sum)
# apply 함수
head(iris)
apply(iris[,1:4],1,mean)
apply(iris[,1:4],1,sum) # 합계
apply(iris[,1:4],2,mean) # 평균
apply(iris[,1:4],2,sd) # 표준편차
# 패키지 설치(gapminder)

# 패키지 불러옴
library(gapminder)
gapminder
* factor는 각각을 구분하는데에 사용
# 나라 이름만 봄
gm <- gapminder
head(gm)
gm[,c("country")]

# 기대수명, 나라 이름만 봄
gm[,c("country", "lifeExp")]
# 기대수명, 나라 이름, 년도만 봄
gm[,c("country", "lifeExp", "year")]

# 1~20개만 보기
gm[1:20,]* ',' 안쓰면 오류 (데이터 프레임이므로)

# 우리나라 정보
gm[gm$country=="Korea, Rep.",]
# 우리나라 인구수
gm[gm$country=="Korea, Rep.","pop"]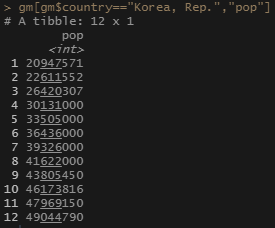
# 우리나라 기대수명과 인구수
gm[gm$country=="Korea, Rep.",c("lifeExp", "pop")]
# 우리나라의 기대수명과 인구의 평균 (apply함수)
apply(gm[gm$country=="Korea, Rep.",c("lifeExp", "pop")], 2, mean)
# 패키지 설치(dplyr)

# 사용자 정의 함수(반환값 여러개일때 인덱스로 접근)
myfunc <- function(x, y){
val.sum <- x+y
val.mul <- x*y
return(list(sum=val.sum, mul=val.mul))
}
result <- myfunc(5,8)
s <- result[1] # result$sum 과 같음
m <- result[2] # result$mul 과 같음
s
m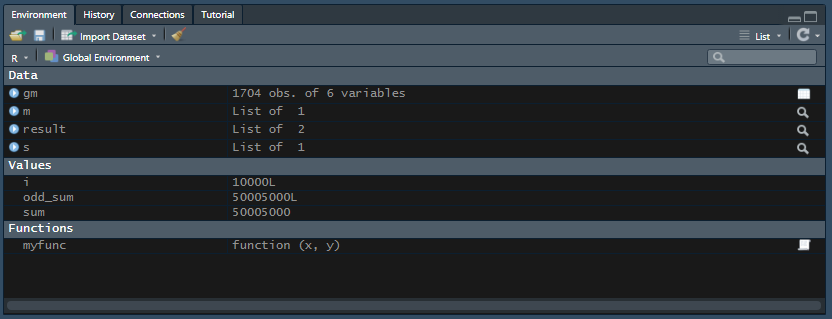
=> function 도 Environment에 저장
# 조건에 맞는 데이터의 위치 찾기
which() : 몇번째인지 인덱스 구함
which.max() : 최댓값이 몇번째인지 인덱스 구함
which.min() : 최솟값이 몇번째인지 인덱스 구함
* arr.ind = True : 각각 하나씩만 해라
# 결측값 처리
is.na함수 : na인 데이터가 있으면 T, 없으면 F
na.omit : na인 데이터 제거(na 포함된 행 제거)
함수의 속성 이용 : na.rm=T로 하면 na 제외하고 연산
airquality
head(airquality)
table(is.na(airquality)) # 결측값이 44개 포함
table(is.na(airquality$Ozone)) #'Ozone'에 결측값이 37개 포함
table(is.na(airquality$Temp)) #'Temp'에 결측값이 없음
mean(airquality$Ozone) # 결측값이 있으므로 평균 구하는 게 정상적으로 이루어지지않음
mean(airquality$Temp) # 결측값이 없으므로 평균 구하는 게 정상적으로 이루어짐
1. !is.na 함수 사용하여 결측값이 아닌 행들을 no_na에 저장
no_na <- airquality[!is.na(airquality$Ozone),] # 'Ozone'에 결측값이 아닌 행들을 no_na에 저장
mean(no_na$Ozone) # 결측값이 없으므로 평균 구하는 게 정상적으로 이루어짐
2. na.omit 함수 사용하여 결측값을 포함하는 행 제거
no_na1 <- na.omit(airquality) # 결측값 포함하는 행 제거
table(is.na(no_na1))
mean(no_na1$Ozone)
3. na.rm=T로 하면 na 제외하고 연산
mean(airquality$Ozone, na.rm=T)
# 이상값(outlier) - 이상한 데이터
이상값을 결측값으로 변경후 제거
# xlsx 패키지 활용
install.packages('xlsx')
library('xlsx')
data <- read.xlsx("daywise.xlsx",sheetIndex = 1)
class(data)
head(data)
str(data)
summary(data)
< daywise.xlsx >

# xml 패키지 활용
먼저 파싱해주고 xml에서 데이터프레임으로 변환시킨 다음
install.packages('XML')
library('XML')
library('methods')
data1 <- xmlParse(file = 'students.xml')
data <- xmlToDataFrame(data1)
data
class(data)
data <- xmlParse(file = 'students.xml')
root_node <- xmlRoot(data)
root_node[2]
data <- xmlParse(file = 'students.xml')
root_node <- xmlRoot(data)
root_node[2]
root_node[[2]][[1]]
< students.xml >

# rjson 패키지 활용
install.packages("rjson")
library("rjson")
data <- fromJSON(file='global-temp.json') # 데이터프레임 아니고 리스트
data <- as.data.frame(data) # 데이터프레임으로 변경
data
data <- t(data)
str(data)
< json 파일>

< 데이터 프레임으로 변환 >

< 전치시킴 >


# dplyr 패키지 활용
library('dplyr')
a <- data.frame(a = 1:2, b = 3:4, c = 5:6)
b <- data.frame(a = 7:8, b = 2:3, c = 3:4, d = 8:9)
a
b
rbind(a,b) # 오류 남 (열의 수 불일치)
rbind(a,a) # 오류 안남 (열의 수 일치)
bind_rows(a,b) # 행으로 결합하고 없는 부분에 NA로 채워짐
a
b
data <- cbind(a,b)
data
data$a
data <- bind_cols(a, b)
data$a...4

# csv 파일 읽기
data <- read.csv("covid_19_data_cleaned.csv")
colnames(data)
head(data)
str(data)
data[2,] # 2행의 데이터 나옴 cols = [Date, Province.State, Country, Lat, Long Confirmed, Recovered, Deaths, Active]
data[c(TRUE, FALSE)] # Date출력, Province.State 출력안함 (한 col씩 띄워서 출력) [Date, Country, Long Recovered Active]
data[c(TRUE, FALSE, FALSE),] # 1번행 다음에 3번행 나옴, [Date, Province.State, Country, Lat, Long Confirmed Recovered Deaths Active]
# 행에 대한 얘기(3씩 간격을 가지고 출력)
# 열은 신경안씀
head(data)
data[data$Country=='US',]
subset(data, Country=='US')
subset(data, Confirmed==max(Confirmed)) # 최고의 날짜정보
subset(data, Deaths==max(Deaths)) # 사망자가 가장 많았던 날
subset(data, Deaths>1e5) # 사망자의 수가 10의 5승보다 많았던 날
# lubridate 패키지 활용
install.packages('lubridate')
library(lubridate)
data$Date
as.Date(data$Date)
data$Date <- mdy(data$Date)
data$Date
dec20 <- subset(data, Date>=as.Date("2020-12-01")) # 12월
jun20 <- subset(data, Date>=as.Date("2020-06-01") & Date<as.Date("2020-07-01")) # 6월
'전공 공부 > 확률및통계' 카테고리의 다른 글
| 확률및통계 2차과제 (0) | 2021.03.28 |
|---|---|
| 확률및통계 4주차 강의 (0) | 2021.03.23 |
| 확률및통계 1차 과제 (0) | 2021.03.14 |
| 확률및통계 2주차 강의 (0) | 2021.03.09 |
| RStudio 설치 (0) | 2021.03.02 |





{kind=link}